Impact écologique de l'intelligence artificielle
Ces prochaines semaines, je vais être amené à parler du Numérique Responsable dans des écoles et universités (et c’est top). Pour l’occasion, je me suis penché un peu plus en détail sur l’impact écologique lié à tout ce qui touche à l’intelligence artificielle. Je me suis aussi intéressé à ce qui est lié à l’éthique et au code inclusif mais ce n’est pas l’objet de cet article.
Je ne suis pas un professionnel de l’intelligence artificielle. Je m’intéresse juste de loin au sujet. N’hésitez donc pas à me signaler d’éventuelles erreurs ou inexactitudes dans cet article.
Pourquoi l’IA pollue
La puissance de calcul utilisée pour la recherche en deep learning double tous les 3-4 mois depuis 2012. Entre 2012 et 2018, elle aurait été multipliée par 300.000. Inversement, le coût des processeurs diminue régulièrement. Ce serait donc dommage de s’en priver.
Ajoutez à cela les tonnes de données qu’il faut fournir pour entraîner les modèles (et qu’il faut donc transporter et stocker).
On retrouve ici les principaux soucis liés à l’impact environnemental du numérique :
- le besoin d’avoir des capacités de calcul de plus en plus conséquentes
- le besoin de brasser des tonnes et des tonnes de données.
Sachant qu’au final 88% des projets de machine learning n’arrivent pas en production.
On retrouve donc là aussi la notion de gaspillage si chère au numérique.
Les racines de la surenchère
L’augmentation du coût environnemental de l’IA est en grande partie due à l’attention portée sur la précision des modèles. En effet, l’enjeu est souvent d’obtenir un modèle le plus précis possible, peu importe ce que ça coûte. On préférera fournir toujours plus de données et exploiter davantage de processeurs (CPU/GPU/TPU) pendant plus longtemps pour peu qu’on ait l’assurance d’y gagner même un peu tout petit peu en précision. Sans tenir compte du fait que la localisation géographique de ces processeurs (comme celle des serveurs où sont stockées les données) conditionne la nature de l’électricité utilisée afin de les alimenter.
Petit rappel : l’idée de base de l’intelligence artificielle est de reproduire autant que possible le fonctionnement du cerveau humain. Ce dernier est un outil très efficace d’un point de vue énergétique et impressionnant au niveau des possibilités. Montrez une girafe à un enfant et il sera capable de la reconnaître dans de multiples contextes. Parfois, il suffit même de décrire la girafe pour qu’il y parvienne.
Pour les machines, c’est un peu plus compliqué. Il faudra souvent fournir des centaines, milliers voire millions de photos de girafes pour qu’il puisse ensuite en reconnaître une avec une précision satisfaisante.
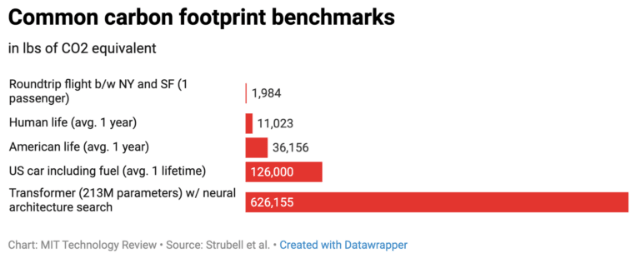
Au final, le coût environnemental d’un modèle est lié principalement à 3 paramètres :
- la taille des jeux de données en entrée
- le nombre de paramètres du modèle (certains parmi les plus récents comptent plus de 100 milliards de paramètres)
- le coût de traitement d’un exemple (fourni pour entraîner le modèle)
Pour limiter le coût de traitement d’un exemple, une piste peut être d’optimiser les calculs effectués.
Des méthodes apparaissent pour réduire la taille des jeux de données en entrée. On parlera par exemple de few-shot learning ou de less than zero-shot learning (ici et là). Une autre solution peut être de mettre à disposition des modèles déjà entraînés.
Plus généralement, il paraît important de repenser la façon dont on perçoit l’intelligence artificielle. En effet, le lien entre le coût d’entraînement et la précision d’un modèle est logarithmique. Dit autrement, plus on investit dans l’entraînement du modèle, plus les bénéfices diminuent. Il convient donc de se fixer des objectifs raisonnable en se plaçant dans une optique d’efficience plutôt que d’augmentation à tout prix. On tend alors vers ce qu’on appelle la GreenAI (source).
Aujourd’hui, on assiste à une surenchère (plus de variables, plus de données, plus de processeurs) qui impacte de plus en plus l’environnement et exclue au passage ceux qui cherchent à innover dans l’intelligence artificielle sans avoir forcément des moyens illimités.
Que faire?
Afin de corriger le tir, plusieurs axes se dessinent.
Le premier revient à adopter les pistes d’amélioration évoquées précédemment (GreenAI et diminution des données en entrée, afin de tendre vers l’efficience). Le but ne doit pas être d’obtenir le modèle le plus précis possible quel que soit le coût. Il vaudrait mieux mettre en avant des modèles qui peuvent devenir suffisamment précis pour un coût aussi faible que possible.
Le second nécessite de revenir dans une optique de sobriété et de s’interroger sur la pertinence de certains modèles. Toutes les utilisations de l’Intelligence Artificielle ne sont pas indispensables voire pertinentes et les enjeux climatiques doivent nous amener à mieux choisir nos priorités. Regardez par exemple comment le machine learning peut aider à lutter contre le changement climatique.
Enfin, le troisième axe nécessite de prendre le temps de mesurer l’impact environnemental de ce que l’on fait. Déjà, quelques outils permettent de calculer cet impact, moyennant quelques approximations :
- https://mlco2.github.io/impact/#publish (et le papier ici)
- https://github.com/Breakend/experiment-impact-tracker
Une ACV (Analyse de Cycle de Vie) peut permettre de mieux comprendre l’impact des différentes étapes de la vie d’un modèle.
Conclusion
Sans surprise, l’Intelligence Artificielle souffre d’une course à la surenchère. Alors que le sujet est de plus en plus omniprésent, il semble indispensable de l’aborder avec sobriété et efficience. Heureusement, les bonnes pratiques sont de mieux en mieux documentées.